Create LLM apps using RAG

If you’re considering making a personalized bot for your documents or your website that responds to you, you’re in the right spot. I’m here to help you create a bot using Langchain and RAG strategies for this purpose.
Understanding the Limitations of ChatGPT and LLMs
ChatGPTs and other Large Language Models (LLMs) are extensively trained on text corpora to comprehend language semantics and coherence. Despite their impressive capabilities, these models have limitations that require careful consideration for particular use cases. One significant challenge is the potential for hallucinations, where the model might generate inaccurate or contextually irrelevant information.
Imagine requesting the model to enhance your company policies; in such scenarios, ChatGPTs and other Large Language Models might struggle to provide factual responses because they lack training on your company’s data. Instead, they may generate nonsensical or irrelevant responses, which can be unhelpful. So, how can we ensure that an LLM comprehends our specific data and generates responses accordingly? This is where techniques like Retrieval Augmentation Generation (RAG) come to the rescue.
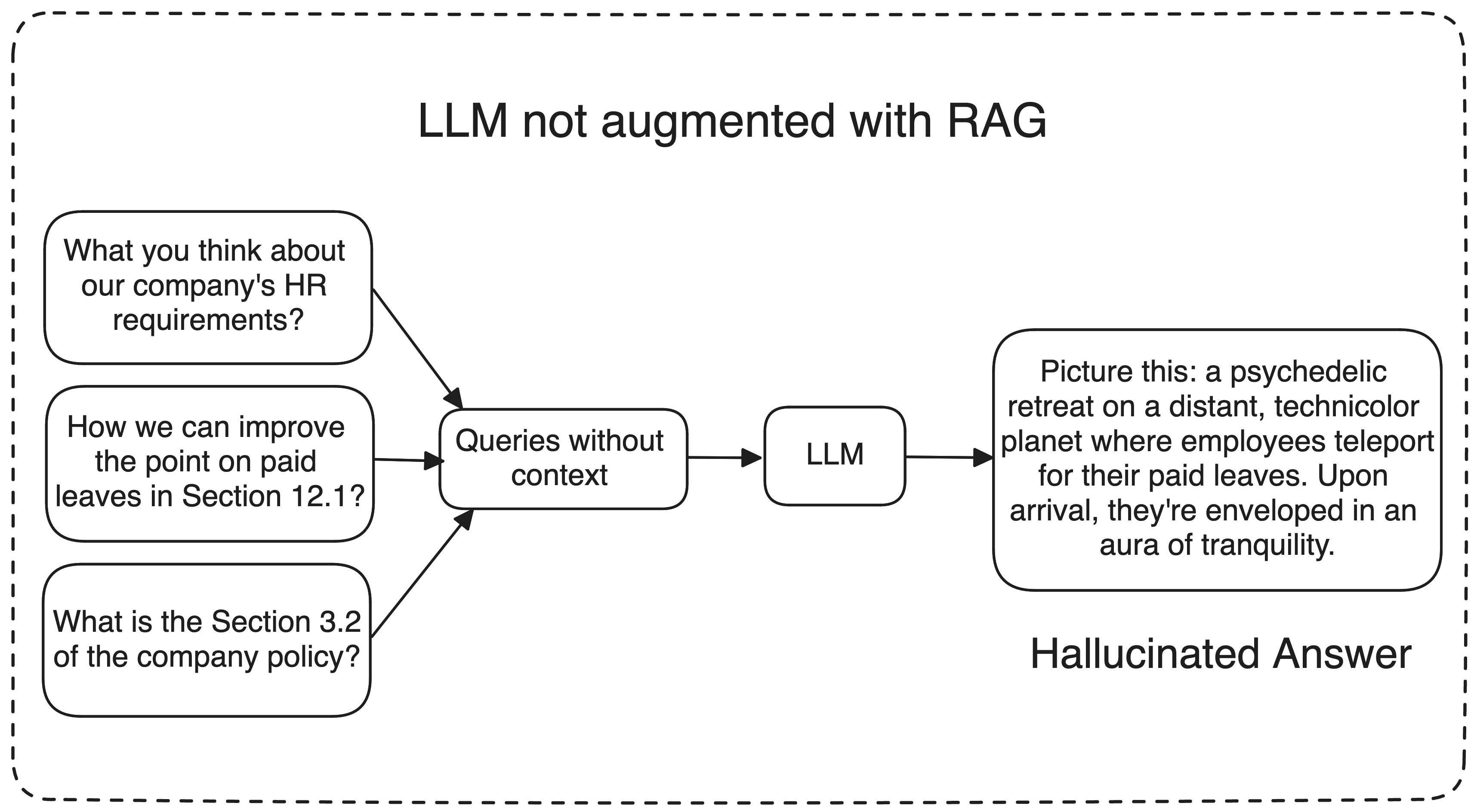
What is RAG?
RAG or Retrieval Augmented Generation uses three main workflows to generate and give the better response
Information Retrieval: When a user asks a question, the AI system retrieves the relevant data from a well-maintained knowledge library or external sources like databases, articles, APIs, or document repositories. This is achieved by converting the query into a numerical format or vector that can be understood by machines.
LLM:The retrieved data is then presented to the LLM or Large Language Model, along with the user’s query. The LLM uses this new knowledge and its training data to generate the response.
Response: Finally, the LLM generates a response that is more accurate and relevant since it has been augmented with the retrieved information. I mean we gave LLM some additional information from our Knowledge library which allows LLMs to provide more contextually relevant and factual responses, solving the problem of models when they are just hallucinating or providing irrelevant answers.
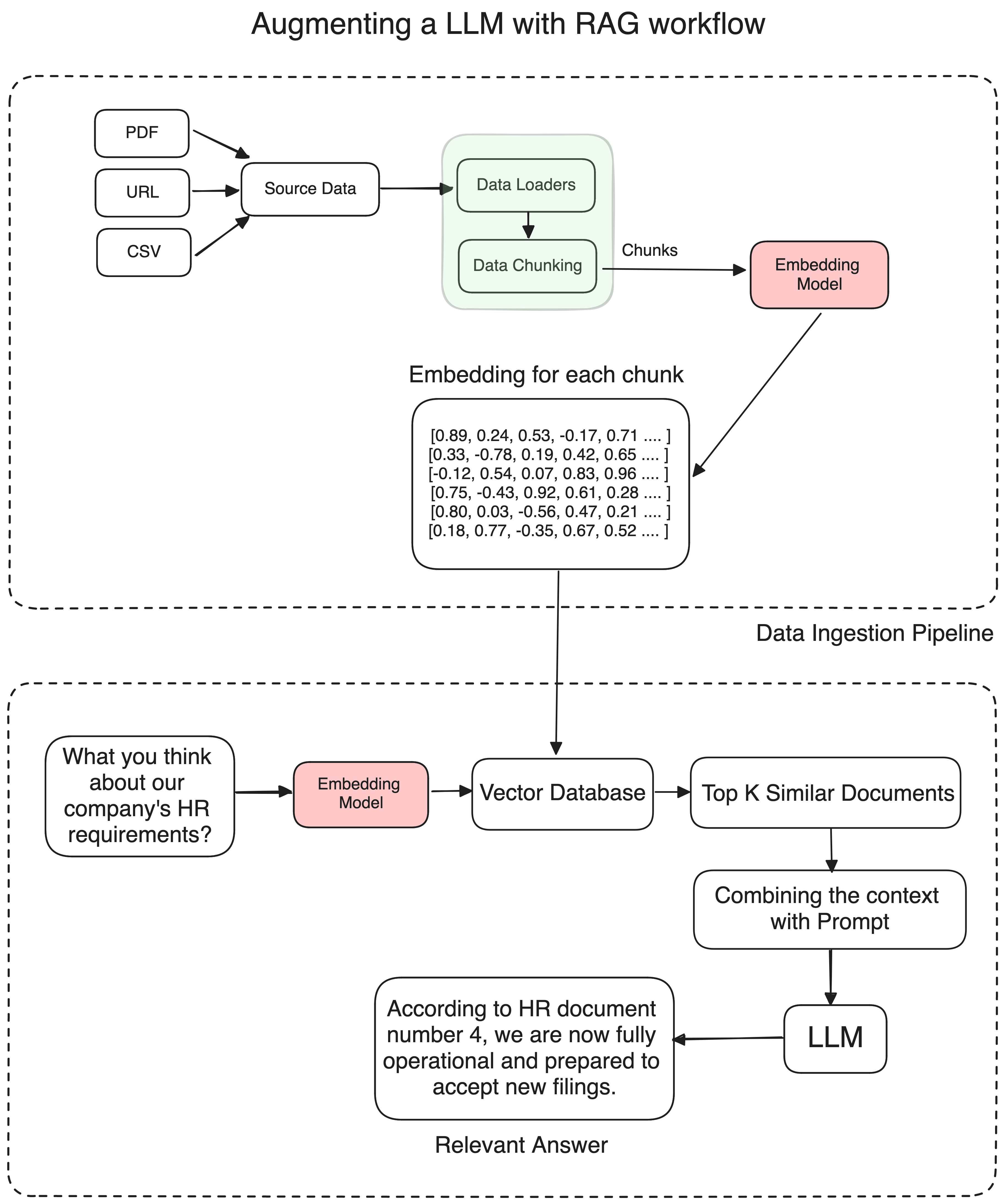
Let’s take the example of company policies again. Suppose you have an HR bot that handles queries related to your Company policies. Now if someone asks anything specific to the policies, The bot can pull the most recent policy documents from the knowledge library, pass the relevant context to a well crafted prompt which is then passed further to the LLM for generating the response.
To make it easier, Imagine a LLM as your knowledgeable friend who seems to know everything, from Geography to Computer Science, from Politics to Philosophy. Now, picture yourself asking this friend a few questions:
- “Who handles my laundry on weekends?”
- “Who lives next door to me?”
- “What brand of peanut butter do I prefer?”
Chances are, your friend wouldn’t be able to answer these questions. Most of the time, no. But let’s say this distant friend becomes closer to you over time, he comes to your place regularly, knows your parents very well, you both hangout pretty often, you go on outings, blah blah blah.. You got the point.
I mean he is gaining access to personal and insider information about you. Now, when you pose the same questions, he can somehow answer those questions with more relevance now because he is better suited with your personal insights.
Similarly, a LLM, when provided with additional information or access to your data, won’t guess or hallucinate. Instead, it can leverage that access data to provide more relevant and accurate answers.
To break it down, here are the exact steps to create any RAG application…
- Extract the relevant information from your data sources.
- Break the information into the small chunks.
- Store the chunks as their embedddings into a vector database.
- Create a prompt template which will be fed to the LLM with the query and the context.
- Convert the query to it’s relevant embedding using same embedding model.
- Fetch k number of relevant documents related to the query from the vector database.
- Pass the relevant documents to the LLM and get the response.
FAQs
We will be using Langchain for this task, Basically it’s like a wrapper which lets you talk and manage your LLM operations better. Note that the Langchain is updating very fast and some functions and other classes might moved to the different modules. So if something doesn’t work, just check if you are importing the libraries from the right sources!
Along with it we will be using Hugging Face, an open-source library for building, training, and deploying state-of-the-art machine learning models, especially about NLP. To use the HuggingFace we need the access token, Get your access token here
For our models, we’ll need two key components: a LLM (Large Language Model) and an embedding model. While paid sources like OpenAI offer these, we’ll be utilizing open-source models to ensure accessibility for everyone.
Now we need a Vector Database to store our embeddings, For that task, we’ve got LanceDB – it’s like a super-smart data lake for handling lots of information. It’s a top-notch vector database, making it the go-to choice for dealing with complex data like vector embeddings.. And the best part? It won’t burn a dent in your pocket because it’s open source and free to use!!
To keep things simple, our data ingestion process will involve using a URL and some PDFs. While you can incorporate additional data sources if needed, we’ll concentrate solely on these two for now.
With Langchain for the interface, Hugging Face for fetching the models, along with open-source components, we’re all set to go! This way, we will save some bucks while still having everything we need. Let’s move to the next steps
Environment Setup
I am using a MacBook Air M1, and it’s important to note that certain dependencies and configurations may vary depending on the type of system you are using. Now open your favorite editor, create a python environment and install the relevant dependencies
# Create a virtual environment
python3 -m venv env
# Activate the virtual environment
source env/bin/activate
# Upgrade pip in the virtual environment
pip install --upgrade pip
# Install required dependencies
pip3 install lancedb langchain langchain_community prettytable sentence-transformers huggingface-hub bs4 pypdf pandas
# This is optional, I did it for removing a warning
pip3 uninstall urllib3
pip3 install 'urllib3<2.0'
Now create a .env file in the same directory to place your Hugging Face api credentials like this
HUGGINGFACEHUB_API_TOKEN = hf_KKNWfBqgwCUOHdHFrBwQ.....
Ensure the name “HUGGINGFACEHUB_API_TOKEN” remains unchanged, as it is crucial for authentication purposes.
If you prefer a straightforward approach without relying on external packages or file loading, you can directly configure the environment variable within your code like this..
HF_TOKEN = "hf_KKNWfBqgwCUOHdHFrBwQ....."
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HF_TOKEN
Finally create a data folder in the project’s root directory, designated as the central repository for storing PDF documents. You can add some sample PDFs for testing purposes; for instance, I am using the Yolo V7 and Transformers paper for demonstration. It’s important to note that this designated folder will function as our primary source for data ingestion.
It seems like everything is in order, and we’re all set!
Step 1 : Extracting the relevant information
To get your RAG application running, the first thing we need to do is to extract the relevant information from the various data sources. It can be a website page, a PDF file, a notion link, a google doc whatever it is, it needs to be extracted from it’s original source first.
import os
from langchain_community.document_loaders import WebBaseLoader, PyPDFLoader, DirectoryLoader
# Put the token values inside the double quotes
HF_TOKEN = "hf_*******"
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HF_TOKEN
# Loading the web url and data
url_loader = WebBaseLoader("https://gameofthrones.fandom.com/wiki/Jon_Snow")
documents_loader = DirectoryLoader('data', glob="./*.pdf", loader_cls=PyPDFLoader)
# Creating the instances
url_docs = url_loader.load()
data_docs = documents_loader.load()
# Combining all the data that we ingested
docs = url_docs + data_docs
This will ingest all the data from the URL link and the PDFs.
Step 2 : Breaking the information into smaller chunks
We’ve all the necessary data for developing our RAG application. Now, it’s time to break down this information into smaller chunks. Later, we’ll utilize an embedding model to convert these chunks into their respective embeddings. But why is it important?
Think of it like this: If you’re tasked with digesting a 100-page book all at once and then asked a specific question about it, it would be challenging to retrieve the necessary information from the entire book to provide an answer. However, if you’re permitted to break the book into smaller, manageable chunks—let’s say 10 pages each—and each chunk is labeled with an index from 0 to 9, the process becomes much simpler. When the same question is posed after this breakdown, you can easily locate the relevant chunk based on its index and then extract the information needed to answer the question accurately.
Picture the book as your extracted information, with each 10-page segment representing a small chunk of data, and the index pages as the embedding. Essentially, we’ll apply an embedding model to these chunks to transform the information into their respective embeddings. While as humans, we may not directly comprehend or relate to these embeddings, they serve as numeric representations of the chunks to our application. This is how you can do this in Python
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1000, chunk_overlap = 50)
chunks = text_splitter.split_documents(docs)
Now the chunk_size parameter specifies the maximum number of characters that a chunk can contain, while the chunk_overlap parameter specifies the number of characters that should overlap between two adjacent chunks. With the chunk_overlap set to 50, the last 50 characters of the adjacent chunks will be shared between each other.
This approach helps to prevent important information from being split across two chunks, ensuring that each chunk contains sufficient contextual information of their neighbor chunks for the subsequent processing or analysis.
Shared information at the boundary of neighboring chunks enables a more seamless transition and understanding of the text’s content. The best strategy for choosing the chunk_size and chunk_overlap parameters largely depends on the nature of the documents and the purpose of the application.
Step 3 : Creating the embeddings and store them into a vectordatabase
There are two primary methods to generate embeddings for our text chunks. The first involves downloading a model, managing preprocessing, and conducting computations independently. Alternatively, we can leverage Hugging Face’s model hub, which offers a variety of pre-trained models for various NLP tasks, including embedding generation.
Opting for the latter approach allows us to utilize one of Hugging Face’s embedding models. With this method, we simply provide our text chunks to the chosen model, saving us from the resource-intensive computations on our local machines. 💀
Hugging Face’s model hub provides numerous options for embedding models, and you can explore the leaderboard to select the most suitable one for your requirements. For now, we’ll proceed with “sentence-transformers/all-MiniLM-L6-v2.” This model is pretty fast and highly efficient in our task!!
from langchain_community.embeddings import HuggingFaceEmbeddings
embedding_model_name = 'sentence-transformers/all-MiniLM-L6-v2'
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_name, model_kwargs={'device': 'cpu'})
Here’s a way to see the number of embeddings for each chunk
query = "Hello I want to see the length of the embeddings for this document."
len(embeddings.embed_documents([query])[0])
# 384
We have the embeddings for our chunks, now we need a vector database to store them.
When it comes to vector databases, there are plenty of options out there suiting various needs. Databases like Pinecone offer adequate performance and advanced features but come with a hefty price tag. On the other hand, open-source alternatives like FAISS or Chroma may lack some extras but are more than sufficient for those not who don’t require extensive scalability.
But wait, I am dropping a bomb here, I’ve recently come across LanceDB, So it’s an open-source vector database similar to FAISS and Chroma. What makes LanceDB stand out is not just its open-source nature but its unparalleled scalability. In fact, after a closer look, I realized that I haven’t done justice in highlighting the true value propositions of LanceDB earlier!!
Surprisingly, LanceDB is the most scalable vector database available, outperforming even the likes of Pinecone, Chroma, Qdrant, and others. Scaling up to a billion vectors locally on your laptop is a feat only achievable with LanceDB. I mean this capability is a game-changer, especially when you compare it to other vector databases struggling even with a hundred million vectors. What’s more mind blowing is that LanceDB manages to offer this unprecedented scalability at a fraction of cost, I mean they are offering the utilities and database tools at much cheaper rates than its closest counterparts.
So now, We’ll create an instance of LanceDB vector database by calling lancedb.connect("lance_database"). This line essentially sets up a connection to the LanceDB database named “lance_database.” Next, we create a table within the database named “rag_sample” using the create_table function. Now we initialzed this table with a single data entry which includes a numeric vector generated by the embed_query function. So text “Hello World” is first converted to it’s numeric representation (fancy name of embeddings) and then it’s mapped to id number 1. Like a key-value pair. Lastly, the mode=”overwrite” parameter ensures that if the table “rag_sample” already exists, it will be overwritten with the new data.
This happens with all the text chunks and it’s quite straightforward. This is how it looks in Python..
import lancedb
from langchain_community.vectorstores import LanceDB
db = lancedb.connect("lance_database")
table = db.create_table(
"rag_sample",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
docsearch = LanceDB.from_documents(chunks, embeddings, connection=table)
NO ROCKET SCIENCE HA!
Step 4 : Create a prompt template which will be fed to the LLM
Ok now comes the prompt template. So when you write a question to the ChatGPT and it answers that question, you are basically providing a prompt to the model so that it can understand what the question is. When companies train the models, they decide what kind of prompt they are going to use for invoking the model and ask the question. For example, if you are working with “Mistral 7B instruct” and you want the optimal results it’s recommended to use the following chat template:
<s>[INST] Instruction [/INST] Model answer</s>[INST] Follow-up instruction [/INST]
Note that <s> and </s> are special tokens to represent beginning of string (BOS) and end of string (EOS) while [INST] and [/INST] are regular strings. It’s just that the Mistral 7B instruct is made in such a way that the model looks for those special tokens to understand the question better. Different types of LLMs have different kinds of instructed prompts.
Now for our case we are going to use huggingfaceh4/zephyr-7b-alpha which is a text generation model. Just to make it clear, Zephyr-7B-α has not been aligned or formated to human preferences with techniques like RLHF (Reinforcement Learning with Human Feedback) or deployed with in-the-loop filtering of responses like ChatGPT, so the model can produce problematic outputs (especially when prompted to do so).
Instead of writing a Prompt of our own, I will use ChatPromptTemplate class which creates a prompt template for the chat models. In layman terms, instead of writing a specified prompt I am letting ChatPromptTemplate to do it for me. Here is an example prompt template that is being generated from the manual messsages.
from langchain_core.prompts import ChatPromptTemplate
chat_template = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
]
)
messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
If you don’t want to write the manual instructions, you can just use the from_template function to generate a more generic prompt template which I used for this project. Here it is..
from langchain_core.prompts import ChatPromptTemplate
template = """
{query}
"""
prompt = ChatPromptTemplate.from_template(template)
Our prompt is set! We’ve crafted a single message, assuming it’s from a human xD . If you’re not using the from_messages function, the ChatPromptTemplate will ensure your prompt works seamlessly with the language model by reserving some additional system messages. There’s always room for improvement with more generic prompts to achieve better results. For now this setup should work..
Step 5 : Convert the query to it’s relevant embedding using same embedding model.
Now, let’s talk about the query or question we want to ask our RAG application. We can’t just pass the query to our model and expect information in return. Instead, we need to pass the query through the same embedding model used for the chunks earlier. Why is this important? Well, by embedding queries, we allow models to compare them efficiently with previously processed chunks of text. This enables tasks like finding similar documents or generating relevant responses.
To understand it better, Imagine you and your friend speak different languages, like English and Hindi, and you need to understand each other’s writings. If your friend hands you a page in Hindi, you won’t understand it directly. So, your friend translates it first, turning the Hindi into English for you. So now if your friend asks you a question in Hindi, you can easily translate that question into English first and look up for the relevant answers in that translated English Text..
Similarly, we initially transformed textual information into their corresponding embeddings. Now, when you pose a query, it undergoes a similar kind of conversion into the numeric form using the same embedding model applied previously to process our textual chunks. This consistent approach allows for efficient retrieval of relevant responses.
Step 6 : Fetch K number of documents.
Now, let’s talk about the retriever. Its job is to dive into the vector database and perform a search to find relevant documents. It returns a set number, let’s call it “k”, of these documents, which are ranked based on their contextual relevance to the query or question you asked. You can set “k” as a parameter, indicating how many relevant documents you want - whether it’s 2, 5, or 10. Generally, if you have a smaller amount of data, it’s best to stick with a lower “k”, around 2. For longer documents or larger datasets, a “k” between 10 and 20 is recommended.
Different search techniques can be employed to fetch relevant documents more effectively and quickly from a vector database. The choice depends on various factors such as your specific use case, the amount of data you have, what kind of vector database you are using and the context of your problem.
retriever = docsearch.as_retriever(search_kwargs={"k": 3})
docs = retriever.get_relevant_documents("what did you know about Yolo V7?")
print(docs)
When you run this code, the retriever will fetch 3 most most relevant documents from the vector database. All these documents will be the contexts for our LLM model to generate the response for our query.
Step 7 : Pass the relevant documents to the LLM and get the response.
So far, we’ve asked our retriever to fetch a set number of relevant documents from the database. Now, we need a language model (LLM) to generate a relevant response based on that context. To ensure robustness, let’s remember that at the beginning of this blog, I mentioned that LLMs like ChatGPT can sometimes generate irrelevant responses, especially when asked about specific use cases or contexts. However, this time, we’re providing the context from our own data to the LLM as a reference. So, it will consider this reference along with its general capabilities to answer the question. That’s the whole idea behind using RAG!
Now, let’s dive into implementing the language model (LLM) aspect of our RAG setup. We’ll be using zephyr model architecture from the Hugging Face Hub. Here’s how we do it in Python:
from langchain_community.llms import HuggingFaceHub
# Model architecture
llm_repo_id = "huggingfaceh4/zephyr-7b-alpha"
model_kwargs = {"temperature": 0.5, "max_length": 4096, "max_new_tokens": 2048}
model = HuggingFaceHub(repo_id=llm_repo_id, model_kwargs=model_kwargs)
In this code snippet, we’re instantiating our language model using the Hugging Face Hub. Specifically, we’re selecting the zephyr 7 billion model which is placed in this repository ID “huggingfaceh4/zephyr-7b-alpha”. Choosing this model isn’t arbitrary; as I said before, it’s based on the model’s suitability for our specific task and requirements. As we are already implementing only Open Source components, Zephyr 7 billion works good enough to generate a useful response with minimal overhead and low latency.
This model comes with some additional parameters to fine-tune its behavior. We’ve set the temperature to 0.5, which controls the randomness of the generated text. As a lower temperature tends to result in more conservative and predictable outputs and when the temperature is set to max which is 1, the model tries to be as creative as it could, so based on what type of output you want for your use case, you can tweak this parameter. For the sake of the simplicity and demonstration purposes, I set it to 0.5 to make sure we get decent results. Next is max_length parameter which defines the maximum length of the generated text and it includes the size of your prompt as well as the response.
max_new_tokens sets the threshold on the maximum number of new tokens that can be generated. As a general rule of thumb, the max_new_tokens should always be less than or equal to the max_length parameter. Why? Think about it..
Step 8 : Create a chain for invoking the LLM.
We have everything we want for our RAG application. The last thing we need to do is to create a chain for invoking the LLM on our query to generate the response. There are different types of chains for the different types of use cases, if you like your LLM to remember the context of the chat over the time like the ChatGPT , you would need a memory instance which can be shared among multiple conversation pieces, for such cases, there are conversational chains available.
For now we just need a chain which can combine our retrieved contexts and pass it with the query to the LLM to generate the response.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever, "query": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
response = rag_chain.invoke("Who killed Jon Snow?")
We have our Prompt, model, context and the query! All of them are combined into a single chain. It’s pretty much what all the chains does! Now before running the final code, I want to give a quick check on these two helper functions: RunnablePassthrough() and StrOutputParser().
The RunnablePassthrough class in LangChain serves to pass inputs unchanged or with additional keys. In our chain, a prompt expects input in the form of a map with keys “context” and “question.” However, user input only includes the “question.” or the “query”. Here, RunnablePassthrough is utilized to pass the user’s question under the “question” key while retrieving the context using a retriever. It just ensures that the input to the prompt conforms to the expected format.
Secondally, StrOutputParser is typically employed in RAG chains to parse the output of the model into a human-readable string. In the layman terms, It is responsible for transforming the model’s output into a more coherent and grammatically correct sentence, which is generally better readable by Humans! That’s it!
D-Day
To make sure we get the entire idea even if the response gets cut off, I’ve implemented a function called get_complete_sentence(). Basically this function helps extract the last complete sentence from the text. So, even if the response hits the maximum token limit that we set upon and it gets truncated midway, we will still get a coherent understanding of the message.
For practical testing, I suggest storing some low sized PDFs in the data folder of your project. You can choose PDFs related to various topics or domains that you want the chatbot to interact with. Additionally, providing a URL as a reference for the chatbot can be helpful for testing. For example, you could use a Wikipedia page, a research paper, or any other online document relevant to your testing goals. During my testing, I used a URL containing information about Jon Snow from Game of Thrones, and PDFs of Transformers paper, and the YOLO V7 paper to evaluate the bot’s performance. Let’s see how our bot performs in varied content.
import os
import time
import lancedb
from langchain_community.vectorstores import LanceDB
from langchain_community.llms import HuggingFaceHub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import LanceDB
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import WebBaseLoader, PyPDFLoader, DirectoryLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from prettytable import PrettyTable
HF_TOKEN = "hf*********"
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HF_TOKEN
# Loading the web URL and breaking down the information into chunks
start_time = time.time()
loader = WebBaseLoader("https://gameofthrones.fandom.com/wiki/Jon_Snow")
documents_loader = DirectoryLoader('data', glob="./*.pdf", loader_cls=PyPDFLoader)
# URL loader
url_docs = loader.load()
# Document loader
data_docs = documents_loader.load()
# Combining all the information into a single variable
docs = url_docs + data_docs
# Specify chunk size and overlap
chunk_size = 256
chunk_overlap = 20
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
chunks = text_splitter.split_documents(docs)
# Specify Embedding Model
embedding_model_name = 'sentence-transformers/all-MiniLM-L6-v2'
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_name, model_kwargs={'device': 'cpu'})
# Specify Vector Database
vectorstore_start_time = time.time()
database_name = "LanceDB"
db = lancedb.connect("src/lance_database")
table = db.create_table(
"rag_sample",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
docsearch = LanceDB.from_documents(chunks, embeddings, connection=table)
vectorstore_end_time = time.time()
# Specify Retrieval Information
search_kwargs = {"k": 3}
retriever = docsearch.as_retriever(search_kwargs = {"k": 3})
# Specify Model Architecture
llm_repo_id = "huggingfaceh4/zephyr-7b-alpha"
model_kwargs = {"temperature": 0.5, "max_length": 4096, "max_new_tokens": 2048}
model = HuggingFaceHub(repo_id=llm_repo_id, model_kwargs=model_kwargs)
template = """
{query}
"""
prompt = ChatPromptTemplate.from_template(template)
rag_chain_start_time = time.time()
rag_chain = (
{"context": retriever, "query": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
rag_chain_end_time = time.time()
def get_complete_sentence(response):
last_period_index = response.rfind('.')
if last_period_index != -1:
return response[:last_period_index + 1]
else:
return response
# Invoke the RAG chain and retrieve the response
rag_invoke_start_time = time.time()
response = rag_chain.invoke("Who killed Jon Snow?")
rag_invoke_end_time = time.time()
# Get the complete sentence
complete_sentence_start_time = time.time()
complete_sentence = get_complete_sentence(response)
complete_sentence_end_time = time.time()
# Create a table
table = PrettyTable()
table.field_names = ["Task", "Time Taken (Seconds)"]
# Add rows to the table
table.add_row(["Vectorstore Creation", round(vectorstore_end_time - vectorstore_start_time, 2)])
table.add_row(["RAG Chain Setup", round(rag_chain_end_time - rag_chain_start_time, 2)])
table.add_row(["RAG Chain Invocation", round(rag_invoke_end_time - rag_invoke_start_time, 2)])
table.add_row(["Complete Sentence Extraction", round(complete_sentence_end_time - complete_sentence_start_time, 2)])
# Additional information in the table
table.add_row(["Embedding Model", embedding_model_name])
table.add_row(["LLM (Language Model) Repo ID", llm_repo_id])
table.add_row(["Vector Database", database_name])
table.add_row(["Temperature", model_kwargs["temperature"]])
table.add_row(["Max Length Tokens", model_kwargs["max_length"]])
table.add_row(["Max New Tokens", model_kwargs["max_new_tokens"]])
table.add_row(["Chunk Size", chunk_size])
table.add_row(["Chunk Overlap", chunk_overlap])
table.add_row(["Number of Documents", len(docs)])
print("\nComplete Sentence:")
print(complete_sentence)
# Print the table
print("\nExecution Timings:")
print(table)
To enhance readability and present the execution information in a structured tabular format, I have used PrettyTable library. You can add it to your virtual environment by using the command pip3 install prettytable.
So this is the response I received in less than < 1 minute, which is quite considerable for the starters. The time it takes can vary depending on your system’s configuration, but I believe you’ll get decent results in just a few minutes. So, please be patient if it’s taking a bit longer.
Human:
Question : Who killed Jon Snow?
Answer:
In the TV series Game of Thrones, Jon Snow was stabbed by his
fellow Night's Watch members in season 5, episode 9,
"The Dance of Dragons." However, he was later resurrected by Melisandre
in season 6, episode 3, "Oathbreaker." So, technically,
no one killed Jon Snow in the show.
Execution Timings:
+------------------------------+----------------------------------------+
| Task | Time Taken (Seconds) |
+------------------------------+----------------------------------------+
| Vectorstore Creation | 16.21 |
| RAG Chain Setup | 0.03 |
| RAG Chain Invocation | 2.06 |
| Complete Sentence Extraction | 0.0 |
| Embedding Model | sentence-transformers/all-MiniLM-L6-v2 |
| LLM (Language Model) Repo ID | huggingfaceh4/zephyr-7b-alpha |
| Vector Database | LanceDB |
| Temperature | 0.5 |
| Max Length Tokens | 4096 |
| Max New Tokens | 2048 |
| Chunk Size | 256 |
| Chunk Overlap | 20 |
| Number of Documents | 39 |
+------------------------------+----------------------------------------+

Have fun experimenting with various data sources! You can try changing the website addresses, adding new PDF files or maybe change the template a bit. LLMs are fun, you never know what you get!
What’s next?
There are plenty of things we can adjust here. We could switch to a more effective embedding model for better indexing, try different searching techniques for the retriever, add a reranker to improve the ranking of documents, or use a more advanced LLM with a larger context window and faster response times. Essentially, every RAG application is just an enhanced version based on these factors. However, the fundamental concept of how a RAG application works always remains the same.
Here is the collab link for the reference..