Databases for ML Worflows

In today’s world, when everyone’s curious about trying out generative AI tools and how they work, you’ve probably heard about embedded databases. Most of us tend to think about client-server based setups when databases come to mind. And honestly, that’s somewhat accurate.
However, client-server architectures aren’t really built to handle heavy analytical and ML workloads. Essentially, the processing tasks fall into two main categories: OLTP (online transactional processing) and OLAP (online analytical processing). So, when you’re changing your Instagram profile picture or uploading a photo on Facebook, you’re essentially involved in OLTP tasks, which focus on quick and easy processing. On the flip side, when we deal with OLAP, it’s all about handling complex computations such as retrieving queries from extensive datasets, combining tables, and aggregating data for big data purposes. Now, we need something that can handle our large ML workloads effectively and perform optimally across datasets ranging from small to large scales.
Columnar Oriented Datastores
Hard drives store data in terms of blocks, so whenever an operation is performed, the entire block containing the data is loaded into memory for reading by the OS. Now, Row-oriented databases aim to store whole rows of the database in the same block, whereas columnar databases store column entries in the same block.
This implies that when you need to perform column-oriented operations like updating columns, aggregations, or selecting a column entry, column-oriented databases outperform row-oriented ones in terms of speed. However, if you need to add a new data point entry with multiple columns, then row-oriented databases perform better.
Now, the point is, there’s something called Apache Arrow, which is a language-agnostic columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware like CPUs and GPUs.
This is too technical. Let me break it down for you. Machine learning is all about feeding huge amounts of data into complex mathematical models to find patterns and make predictions, right? Now, Apache Arrow turbocharges this process by providing a standardized way to store and work with data that’s optimized for modern hardware like powerful GPUs. So Instead of dealing with clunky row-based formats, Arrow’s columnar layout lets you focus on the specific data features you need, drastically cutting down processing time. And since Arrow keeps data in memory, AKA RAM, rather than on sluggish disk storage like hard drives or SSDs, your models can crunch through datasets at blistering speeds. The end result? You can iterate faster, train better models, and stay ahead of the competition.
Still confused, right? I was too. Well, let’s take an example. If you’re building a model to predict housing prices based on factors like square footage, number of bedrooms, location, etc., Arrow’s columnar format would allow you to easily isolate and work with just the columns containing those specific features, ignoring any other irrelevant data columns. This focused, selective data access is more efficient than dealing with row-based formats where you’d have to sort through all the data indiscriminately.
Now that’s where the power of Arrow based columnar databases comes into play.
Lance Data Format
Building on the advantages of Apache Arrow’s columnar, in-memory approach for machine learning, there’s another game-changing data format that takes things to a whole new level – the Lance Data Format.
Designed from the ground up with modern ML workflows in mind, Lance is an absolute speed demon when it comes to querying and prepping data for training models. But it’s not just about raw speed – Lance has some seriously impressive versatility under the hood.
Unlike formats limited to tabular data, Lance can handle all kinds of data types like images, videos, 3D point clouds, audio, and more. It’s like a Swiss Army knife of data formats for ML. Btw, Don’t just take my word for it because I love LanceDB, instead – benchmarks have shown that Lance can provide random data access involving read and write operation a mind-boggling approximately 1000 times faster than Parquet, another popular columnar format. This blistering speed comes from unique storage memory layout used by Lance.
The other important thing LanceDB provides is the usage of Zero-copy versioning, essentially it means that when you create a new version of your data, LanceDB doesn’t have to make an entire copy – it just stores the changes efficiently. This saves a ton of time and storage space compared to traditional versioning methods. And optimized vector operations allow Lance to process data in bulk, taking full advantage of modern hardware like GPUs and vectorized CPUs. It’s all part of Lance’s cloud-native design.
In-process
Before understanding what Embedded Systems really do, First, we need to understand what a database management system (DBMS) is in Layman. Now in simple terms a DBMS is a software system that allows you to create, manage, and interact with databases (obviously duhh). I mean It provides a way to store, retrieve, and manipulate data in an organized and more efficient manner.
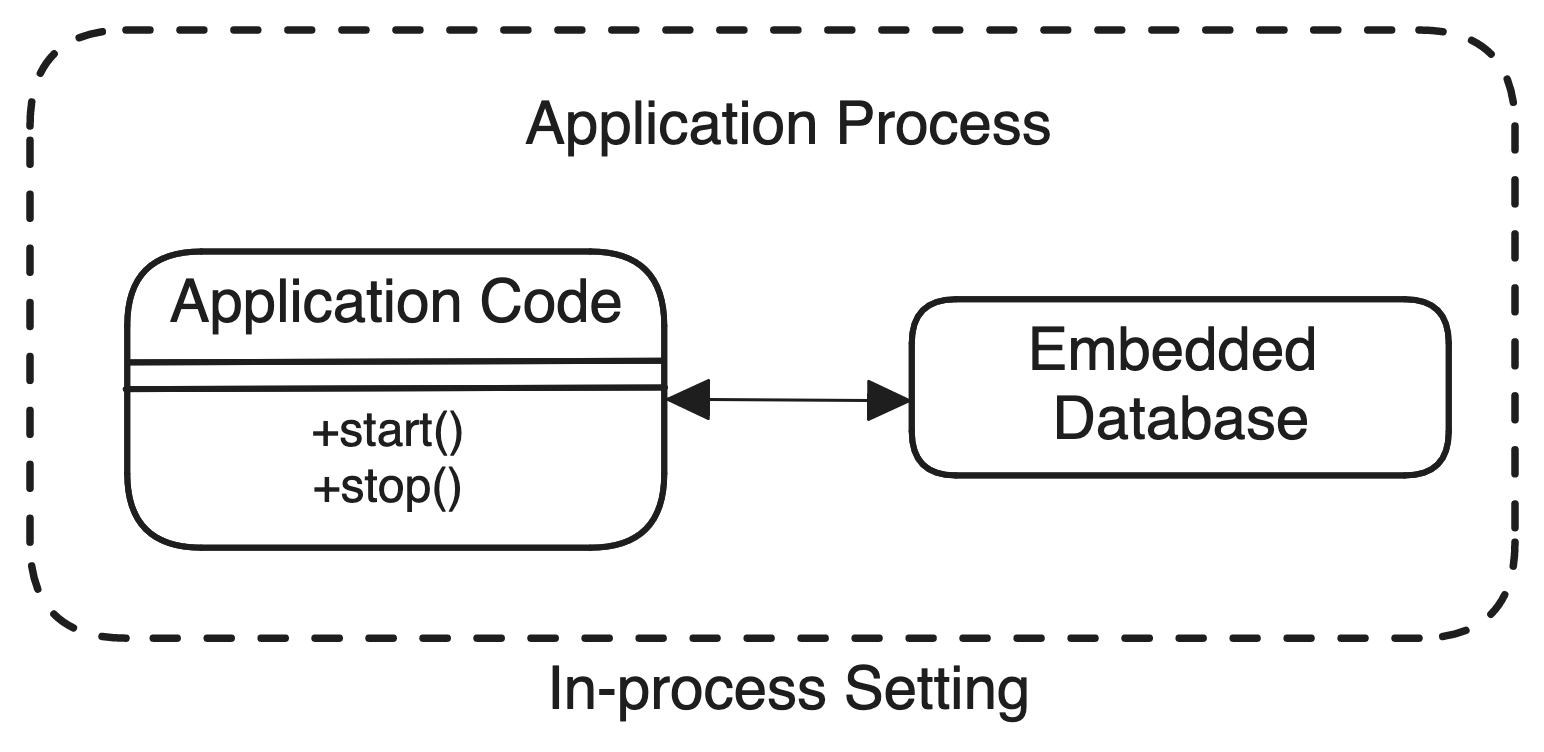
Now, an embedded database is a type of DBMS that is tightly integrated with the application layer. This means that the database that you are working with is not a separate process or service running on its own; instead, it runs within the same process as the application itself.
This tight integration makes it easier for the application to interact with the database, as there’s no need for inter-process communication or network communication unlike traditional client-server database systems where the database is a separate process or a service
This type of thing is called “in-process”. Remember this for the rest of your life. It might be the most important thing to remember when judging the other embedded databases out there.
In simple terms, the application can directly access and manipulate the database without going through additional layers or protocols. CUTTING THE BS.
On-disk storage
Remember I said earlier that Embedded systems have this ability to store the data in-memory and work at blistering speeds. While embedded databases can store data in memory, they also have this capability to store larger datasets on disk. This allows them to scale to large amounts of data (terabytes or billion dataset points, think of embeddings of billion tokens) while still providing relatively low query latencies and response times. So it’s like the best of the both worlds.
Serverless
Ok new term! Sometimes the terms “Embedded” and “Serverless” are sometimes used interchangeably in the database community, but they actually refer to different concepts. “Embedded” refers to the database being tightly integrated with the application as we seen earlier in case of Embedded databases while Serverless refers to the separation of storage and compute resources, and it’s often used in the context of microservices architectures.
To make it more concise, think of the serverless database as it’s composed of two different containers, the storage layer (where the data is stored) and the compute layer (where the data is processed). Now this separation allows the compute resources to be dynamically allocated and scaled up or down based on the workload.
And btw, when we are talking about the Serverless model, it is often associated with the cloud based services, where you don’t have to manage the underlying infra..
Scalability

Ok so you decided to work on the simple RAG system and wanted to test it out or just maybe play with it and came up with the various vector databases, you did your experiment, you are happy and done. Now when you got serious and came up with something and wanted to scale your RAG system for let’s say 1 billion embeddings, you open up your earlier setup, ingested more data, created more embeddings and when the time came, your traditional embedding database gave you nightmares in terms of the latency as well as stability.
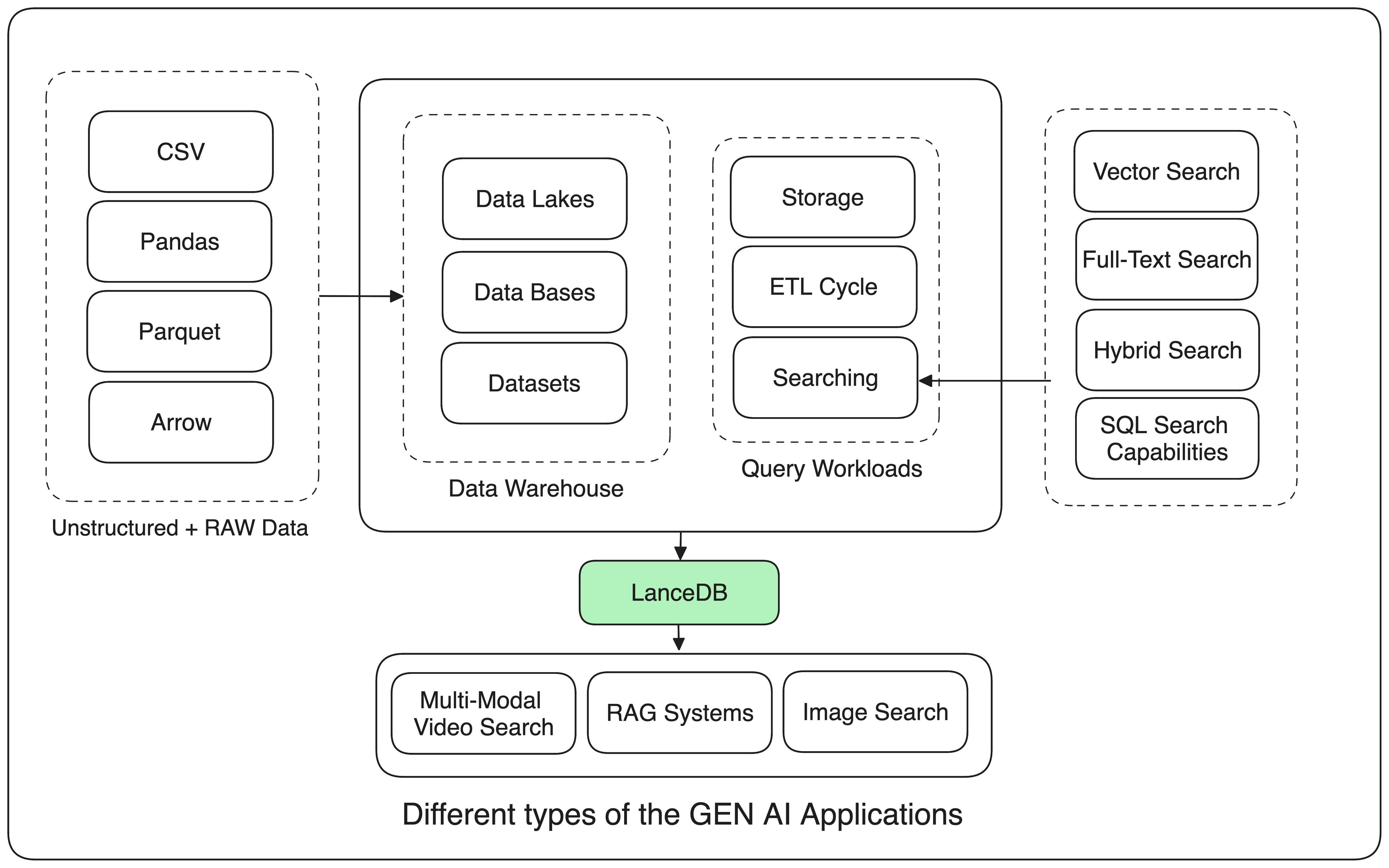
Now, Think of an open-source embedding database designed to seamlessly handle a variety of setups and effortlessly scales up to billions of vectors locally., scales up to billions of embeddings, fetch the relevant embeddings with amazing searching capabilities and data never leaves your local machine, feels too good to be true right?! Well there is LanceDB again. I mean from the moment you dirty your hands for your next RAG system all upto the time you put something as big as production, LanceDB scales amazingly well…
Multimodality

The current embedded databases should not only support textual data but also be compatible with various file formats. It’s no longer just about text ingestion. Some time ago, I developed a GTA-5 multimodal RAG application that displays the GTA5 landscape upon entering a query. I highly recommend giving it a read to understand why the Multimodal RAG system is the new hotshot and why companies are eager to integrate it into their core. Honestly, I haven’t come across any embedded vector database other than LanceDB that can effortlessly ingest any kind of file format.
By the way, multimodality does make sense because LanceDB is built on top of the Lance format. As mentioned earlier, it supports diverse data types, including images, audio, and text, making it incredibly flexible for applications with various data formats.
Searching and Integrations
Ok, so we stored the Embeddings, we scaled our RAG too, now for a given query, we want to find the relevant embeddings, and that’s where LanceDB shines. Now Searching in LanceDB is as easy as it could be, you can just query your data in a number of ways - via SQL, full-text search , and vector search. As it supports the Hybrid search too which is one of the biggest favorable for the amazing search capabilities in LanceDB.
But it’s not just about searching guys, it integrates well enough with native Python, JavaScript/TypeScript, Pandas, Pydantic, that means you can easily integrate it with your favorite programming languages, in addition to that, it has direct integrations with cloud storage providers like AWS S3 and Azure Blob Storage. This means that we can directly query data stored on the cloud, without any added ETL steps.

Woah, I do love LanceDB
More or less, we looked at these things right :
- Columnar Oriented Databases
- Lance Format
- In-process
- On-disk storage
- Serverless
- Embedded systems.
- Scalability
- Multimodality
- Searching and Integrations
Well all of them are bundled together with no cost upfront, ready to serve in one installation click and voila baby, you have your new best friend, maybe more than that, who knows? So what are you waiting for? Here is the reference, see you soon.